[쿠버네티스] Probe란? (Liveness, Readiness, Startup)
Probe
probe는 쿠버네티스에서 컨테이너 상태를 주기적으로 진단하기 위해 사용되는 기능입니다. 이를 통해 쿠버네티스는 각 컨테이너의 상태를 체크하고 문제가 발생한 경우에는 해당 컨테이너를 자동으로 재시작하거나 서비스에서 제외할 수 있습니다.
Probe의 종류는 총 3가지가 있습니다.
- ReadinessProbe
- Liveness Probe
- Startup Probe
각 probe의 세부 기능은 다음과 같습니다.
ReadinessProbe
쿠버네티스의 ReadinessProbe는 컨테이너가 애플리케이션 요청을 처리할 준비가 되었는지를 판단하는 헬스 체크 메커니즘입니다. 이를 통해 아직 초기화 중이거나 준비되지 않은 상태의 Pod가 서비스의 엔드포인트에 포함되지 않도록 관리할 수 있습니다.
주요 특징 및 역할
- 애플리케이션 준비 상태 확인
컨테이너 내부 애플리케이션이 초기화 과정 중이거나 필요한 종속성을 모두 준비하기 전에는 외부 요청을 처리하지 않아야 합니다. ReadinessProbe는 이 상태를 주기적으로 체크하여, 준비가 완료된 후에만 트래픽을 전달하도록 합니다. - 서비스 엔드포인트 관리
쿠버네티스 서비스는 ReadinessProbe의 결과를 참조하여, 응답이 없는 또는 실패한 Pod를 엔드포인트 목록에서 자동으로 제외합니다. 이렇게 함으로써 클라이언트 요청이 준비되지 않은 Pod로 전달되는 것을 방지합니다.

LivenessProbe
쿠버네티스의 livenessProbe는 컨테이너가 정상적으로 동작하고 있는지(살아있는지)를 주기적으로 확인하는 헬스 체크 메커니즘입니다. 만약 livenessProbe 검사에서 실패할 경우, 쿠버네티스는 해당 컨테이너가 장애 상태에 빠졌다고 판단하여 자동으로 재시작합니다. 이를 통해 애플리케이션이 멈추거나 비정상적인 상태에 빠졌을 때 신속하게 복구할 수 있습니다.
주요 특징
- 자동 복구 기능:
livenessProbe가 연속적인 실패를 감지하면, 쿠버네티스는 해당 컨테이너를 종료한 후 자동으로 재시작합니다. 이 과정은 장애 상태에서 신속하게 복구하는 구체적인 동작 방식입니다. - 자체 치유(Self-healing):
자동 복구 기능 덕분에 시스템 전체는 장애 발생 시 스스로 회복할 수 있습니다. 즉, 컨테이너의 재시작이 반복적으로 수행되면서 전체 시스템의 안정성과 가용성이 유지되는 점을 의미합니다.
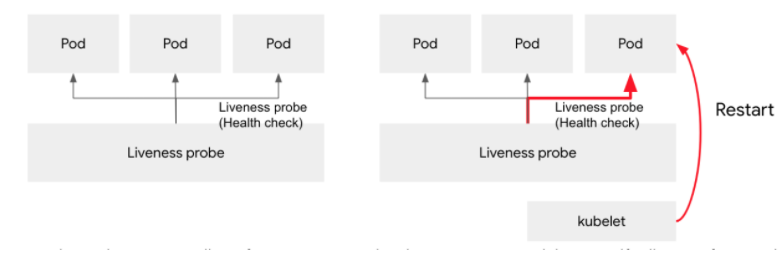
* Liveness Probe는 컨테이너 상태가 비정상이라고 판단하면, 해당 Pod를 재시작하는 반면 ReadinessProbe는 해당 Pod를 사용할 수 없음으로 체크하고 서비스 등에서 제외
StartupProbe
쿠버네티스의 Startup Probe는 컨테이너가 시작 과정에서 시간이 오래 걸리는 애플리케이션을 위해 도입된 헬스 체크 메커니즘입니다. 기존의 liveness 또는 readiness probe가 너무 일찍 작동하여 아직 초기화 중인 컨테이너를 장애로 잘못 판단해 재시작하는 문제를 방지할 목적으로 사용됩니다.
주요 특징
- 컨테이너 초기화 지원:
Startup Probe는 애플리케이션이 초기화되는 동안 별도의 체크를 수행합니다. 이 기간 동안 liveness probe의 체크는 보류되며, Startup Probe가 성공적으로 완료되면 이후부터 liveness probe가 작동하게 됩니다. - 다양한 체크 방식 지원:
다른 프로브와 마찬가지로, Startup Probe 역시 exec, HTTP GET, TCP Socket 등의 방식을 이용할 수 있습니다. 이를 통해 애플리케이션의 시작 준비 상태를 다양한 방식으로 확인할 수 있습니다. - 긴 초기화 시간 허용:
초기화에 시간이 오래 걸리는 애플리케이션의 경우, Startup Probe의 failureThreshold와 periodSeconds를 조정하여 충분한 시간을 제공할 수 있습니다. 이로 인해 불필요한 컨테이너 재시작을 방지할 수 있습니다.
동작 방식
- 컨테이너 시작:
컨테이너가 시작되면, Startup Probe가 주기적으로 애플리케이션의 초기화 상태를 확인합니다. - 성공 판단:
Startup Probe가 성공하면, 해당 컨테이너는 초기화가 완료된 것으로 판단되고, 이후부터는 liveness probe 및 readiness probe가 정상적으로 작동합니다. - 실패 시 조치:
만약 Startup Probe가 설정된 시간 내에 성공하지 못하면, 쿠버네티스는 해당 컨테이너를 재시작하여 초기화 과정을 다시 시도합니다.
Handler
쿠버네티스에서는 Pod의 상태를 확인하기 위해 여러 가지 방식의 Handler를 지원합니다. 주로 사용되는 방식은 아래와 같습니다.
1. Exec 방식 (Command)
- 동작 원리:
컨테이너 내부에서 특정 명령어를 실행합니다. 이때 명령어의 종료 코드(exit code)가 0이면 정상으로 간주하고, 0이 아니면 비정상 상태로 판단합니다. - 사용 예시:
예를 들어, 애플리케이션 내부에 /health 스크립트를 두고 이를 실행하여 결과를 확인할 수 있습니다.
apiVersion: v1
kind: Pod
metadata:
name: exec-probe-pod
spec:
containers:
- name: myapp
image: myapp:latest
# 컨테이너가 계속 실행되도록 간단한 쉘 루프 실행
command: ["/bin/sh", "-c", "while true; do sleep 5; done"]
livenessProbe:
exec:
command:
- /health
initialDelaySeconds: 5 # 컨테이너 시작 후 5초 후에 처음 검사 시작
periodSeconds: 10 # 10초마다 검사를 수행
2. HTTP GET 방식
- 동작 원리:
지정된 URL 경로로 HTTP GET 요청을 보내고, 응답 코드가 200번대(혹은 사용자가 설정한 정상 범위)에 해당하면 정상으로 판단합니다. - 사용 예시:
웹 애플리케이션의 경우, /status 또는 /health와 같은 엔드포인트를 만들어 두고 해당 엔드포인트의 응답을 확인할 수 있습니다.
apiVersion: v1
kind: Pod
metadata:
name: http-probe-pod
spec:
containers:
- name: myapp
image: myapp:latest
ports:
- containerPort: 8080
command: ["/bin/sh", "-c", "while true; do sleep 5; done"]
readinessProbe:
httpGet:
path: /status
port: 8080
initialDelaySeconds: 5 # 컨테이너 시작 후 5초 후에 처음 검사 시작
periodSeconds: 10 # 10초마다 엔드포인트를 검사3. TCP Socket 방식
- 동작 원리:
지정된 호스트와 포트에 대해 TCP 연결을 시도합니다. 연결이 성공하면 정상, 연결에 실패하면 비정상 상태로 판단합니다. - 사용 예시:
데이터베이스나 TCP 기반 서비스를 제공하는 애플리케이션의 경우, 해당 포트에 연결 가능 여부를 통해 상태를 확인할 수 있습니다.
apiVersion: v1
kind: Pod
metadata:
name: tcp-probe-pod
spec:
containers:
- name: myapp
image: myapp:latest
ports:
- containerPort: 3306
command: ["/bin/sh", "-c", "while true; do sleep 5; done"]
livenessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 5 # 컨테이너 시작 후 5초 후에 처음 검사 시작
periodSeconds: 10 # 10초마다 TCP 연결 시도추가 설정 옵션
각 Probe 방식은 아래와 같은 추가 설정 옵션들을 지원하여, 애플리케이션의 특성에 맞게 동작을 세밀하게 제어할 수 있습니다.
- initialDelaySeconds:
컨테이너 시작 후 처음 Probe를 수행하기 전까지 기다리는 시간입니다. - periodSeconds:
Probe를 주기적으로 수행하는 간격을 설정합니다. - timeoutSeconds:
Probe의 응답을 기다리는 최대 시간을 지정합니다. - successThreshold & failureThreshold:
정상 및 실패로 판단하기 위해 연속적으로 요구되는 성공 혹은 실패 횟수를 설정할 수 있습니다.
이처럼 각 Probe 방식은 애플리케이션의 종류와 요구사항에 따라 유연하게 선택되고 설정되어, Pod의 상태를 효과적으로 관리하고 서비스의 안정성을 높이는 역할을 합니다.
그러면 이들은 언제 사용 될까?
필자가 이해한바로 설명하겠습니다.
만약 Pod하나가 장애를 일으켰을 때,
Readiness Probe에서는 장애가 발생한 Pod를 서비스 엔드 포인트에서 제외시켜 트래픽을 전달하지 않는 역할을 합니다.
반면 Liveness Probe에서는 해당 Pod를 재시작하여 복구하는 역할을 합니다.
일반적으로 컨테이너가 실행되면 Readiness와 Liveness Probe가 동시에 주기적으로 실행됩니다.
다만 Startup Probe를 사용하는 경우에는 컨테이너가 초기화 완료될 때까지 Liveness Probe의 체크가 일시 중단됩니다.
즉 StartupProbe는 긴 초기화 시간이 필요한 애플리케이션에서, 초기화 도중 Liveness Probe가 너무 일찍 작동해 컨테이너를 재시작하는 것을 방지하기 위해 사용됩니다. Startup Probe가 성공해야 그 이후에 Liveness Probe가 활성화되고, 동시에 Readiness Probe도 계속 작동하여 서비스 준비 여부를 판단합니다.
참고:
https://www.youtube.com/playlist?list=PLApuRlvrZKohaBHvXAOhUD-RxD0uQ3z0c